清华徐昆团队 | 基于合成数据的对比自监督表征学习
发布时间:2021-10-20论文题名:Contrastive Self-supervised Representation Learning Using Synthetic Data
论文作者:Dong-Yu She, Kun Xu
全文链接:https://link.springer.com/article/10.1007/s11633-021-1297-9
参考链接:https://mp.weixin.qq.com/s/ESTeqIrtAcxwtqVy1o2IkQ
利用深度神经网络学习视觉表征往往需要大量的人工标记数据,从现实生活场景中获取这些数据代价较高。近年来,将输入本身作为监督信息的自监督学习因其在视觉表征学习(visual representation learning)方面的优异性能而备受青睐。清华大学徐昆副教授团队提出一种对比自监督框架(contrastive self-supervised framework)用以在合成数据中学习通用的视觉表征,合成数据具有完全可控且容易获取的特点,为了减小真实数据与合成数据间存在的领域差异问题,团队还采用了一种基于对抗训练的特征级域自适应技术。实验表明,该方法在多个视觉识别数据集上取得了良好效果。相关成果已发表于IJAC,全文开放获取!

图片来自Springer
卷积神经网络(Convolutional neural networks, ConvNets)在计算机视觉领域取得了巨大进展。然而,这些成就需要基于大量训练数据的网络监督学习的支撑。近期工作尝试从没有任何人工标记的大规模无标记数据中学习视觉表征。其中具有代表性的方法就是自监督学习,该类方法先定义一个无需人工标签的辅助任务,基于输入本身构造监督信号来训练网络。使其通过完成诸如推断几何构造或恢复图像缺失部分等任务学习到具有语义信息的表征。
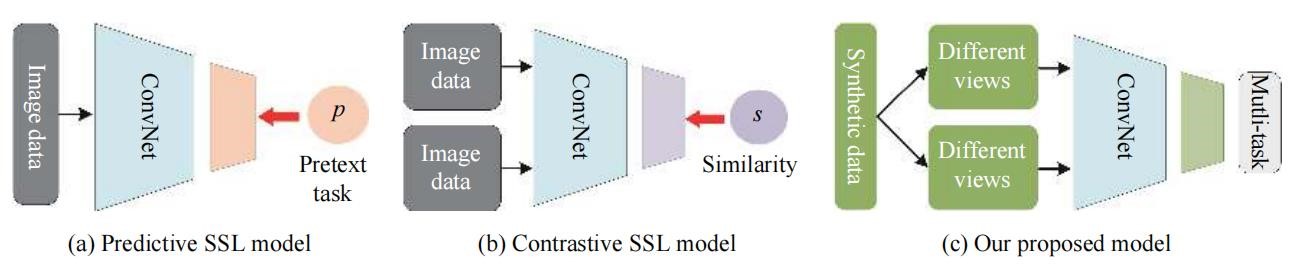
不同学习模型(图片来自论文)
有别于现有从真实数据中学习表征的自监督学习工作,本文旨在利用合成数据及其自动获取的标签来学习视觉任务通用的表征。与从现实世界中收集和标记的照片相比,合成数据更易获取且成本较低。举例来说,实际拍摄一些物体(如鸟类)的照片较为费时且获取的视角信息有限,而合成场景的全景视图却很容易得到。人们可以完全控制和获取合成数据的属性,如光照、物理信息、位姿等,利用这些数据增强模型的鲁棒性。
本文提出一种多任务自监督框架,利用合成数据中的语义信息学习通用视觉表征。具体而言,在合成场景中,本文提出的框架通过对比损失使得同一场景中不同视角的一致性达到最大化,并同时预测自动计算得到的物理线索,包括深度、实例轮廓图和表面法向图。此外,为解决合成图片与真实图片之间的域差异,本文还采用了一种基于对抗训练的特征级域自适应技术。实验验证了该方法在自监督学习中的有效性,实验结果达到现有最好水平。
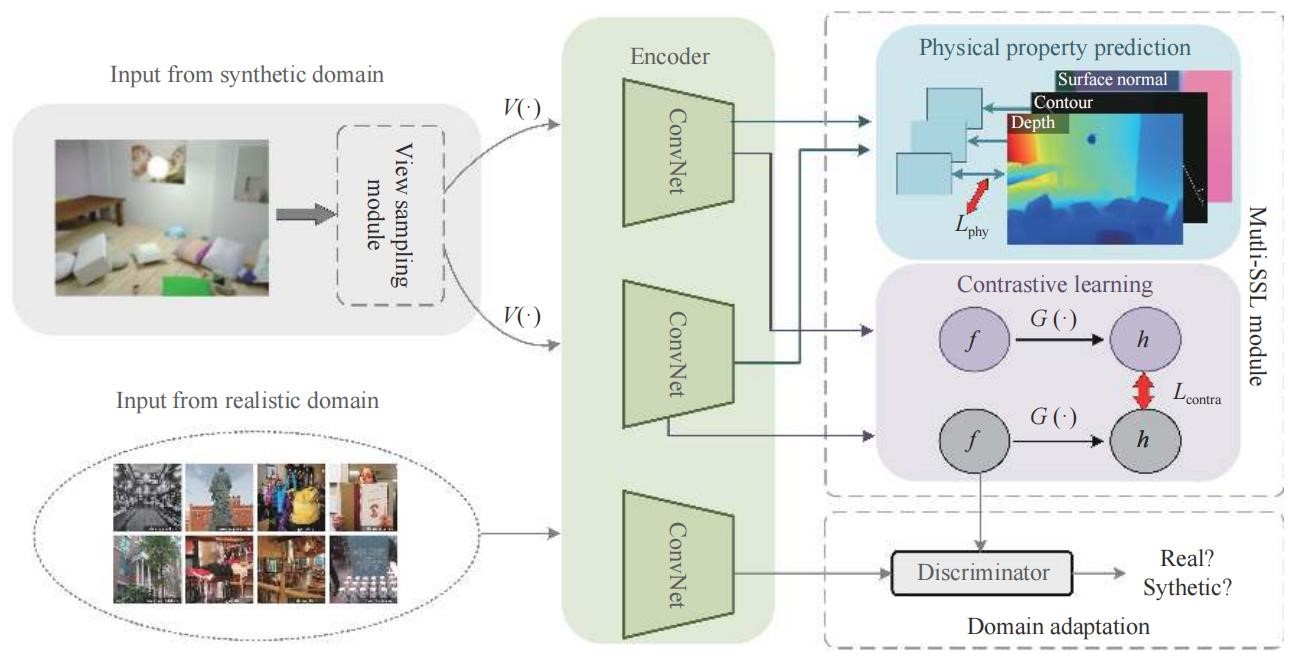
本文所提框架(图片来自论文)
本文的其余部分组织如下:第2节总结了自监督学习方法的相关工作。第3节介绍了本文提出的合成数据表征学习框架。在第4节中,我们给出了在常用基准数据集上的实验结果。最后,第5节对本文进行了总结。
来源:《International Journal of Automation and Computing》编辑部

